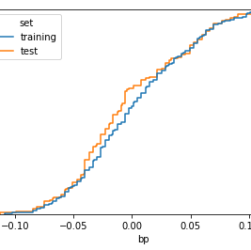
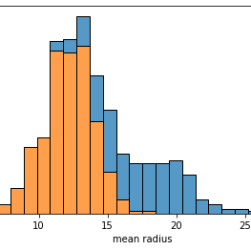
Dealing with unbalanced datasets is always hard for a data scientist. Such datasets can create trouble for our machine learning models if we don’t deal with them properly. So, measuring how much our dataset is unbalanced is important before taking the proper precautions. In this article, I suggest some possible techniques.