Data pre-processing is an important part of every machine learning project. That’s why I’ve created a best-seller online course about this topic. A very useful transformation to be applied to data is normalization. Some models require it as mandatory to work properly. Let’s see some of them.
What is normalization?
Normalization is a general term related to the scaling of the variables. Scaling transforms a set of variables into a new set of variables that have the same order of magnitude. It’s usually a linear transformation, so it doesn’t affect the correlation or the predictive power of the features.
Why do we need to normalize our data? Because some models are sensitive to the order of magnitude of the features. If a feature has an order of magnitude equal to 1000, for example, and another feature has an order of magnitude equal to 10, some models may “think” that the first feature is more important than the second one. It’s obviously a bias, because the order of magnitude doesn’t give us any information about the predictive power. So, we need to remove this bias by transforming the variables to give them the same order of magnitude. This is the role of the scaling transformations.
Such transformations can be normalization (which transforms each variable into a 0-1 interval) and standardization (which transforms each variable into a 0-mean and unit variance variable). I talk about these transformations extensively in another article. According to my experience, standardization works better because it doesn’t shrink the probability distribution of a variable if there are outliers as, for example, normalization does. So, I’ll talk about standardization during the entire article.
Models that require normalization
Let’s see some models that require scaling before training. For the following examples, I’ll use Python code and the Pipeline object of scikit-learn, which performs a sequence of transformations before applying a model and returns an object that can be called as it was a model itself.
The scaling function I’m going to use is the standardization, performed by the StandardScaler object.
Linear models
All the linear models but linear regression actually require normalization. Lasso, Ridge and Elastic Net regressions are powerful models, but they require normalization because the penalty coefficients are the same for all the variables.
lasso = make_pipeline(StandardScaler(), Lasso())
ridge = make_pipeline(StandardScaler(), Ridge())
en = make_pipeline(StandardScaler(), ElasticNet()) Logistic regression requires normalization as well in order to avoid the vanishing gradient problem during the training phase.
logistic = make_pipeline(StandardScaler(), LogisticRegression())If you train a linear regression without previous normalization, you can’t use the coefficients as indicators of feature importance. If you need to perform feature importance (for example, for dimensionality reduction purposes), you must normalize your dataset in advance, even if you work with a simple linear regression.
lr = make_pipeline(StandardScaler(), LinearRegression())Support Vector Machines
Support Vector Machines are powerful models based on distances. They try to find a hyperplane in the vector space of the features that is able to linearly separate the training records according to the value of the target variable.

With some changes, SVM can be used even with non-linear functions and for regression purposes.
Since distances are very sensitive to the order of magnitude of the features, it’s necessary to apply scaling transformations for SVM as well.
svm_c = make_pipeline(StandardScaler(), LinearSVC()) # For classification
svm_r = make_pipeline(StandardScaler(), LinearSVR()) # For regressionk-nearest neighbors
KNN is a very popular algorithm based on distances (typically Euclidean distance). The prediction considers the k nearest neighbors to a given point in the space of the features.
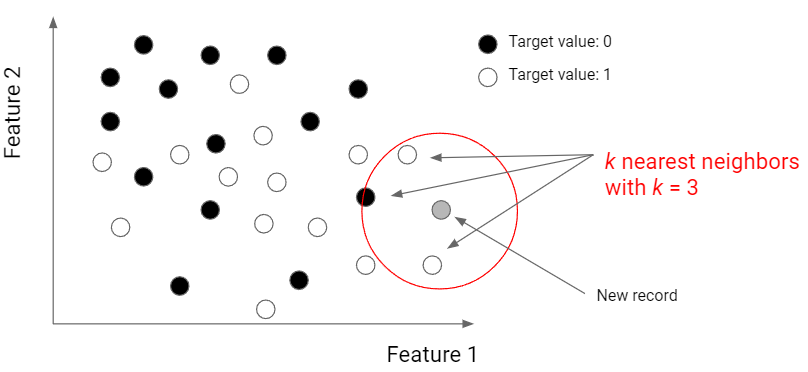
Just like SVM, even KNN requires working with normalized data.
knn_c = make_pipeline(StandardScaler(), KNeighborsClassifier()) # For classification
knn_r = make_pipeline(StandardScaler(), KNeighborsRegressor()) # For regressionNeural networks
Finally, the neural networks are very sensitive to the order of magnitude of the features. The activation functions always require normalized data, otherwise the training phase will suffer from the vanishing Gradient problem just like the logistic regression.
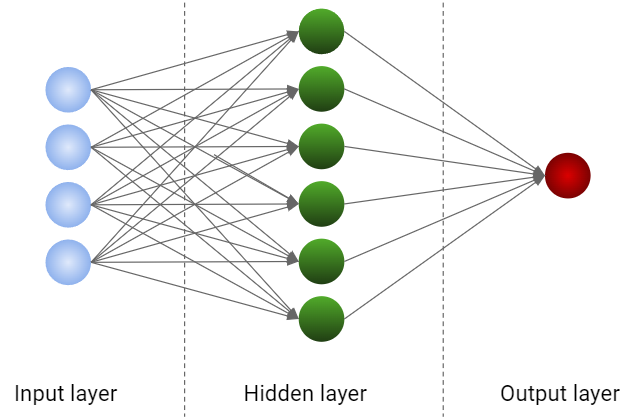
nn_c = make_pipeline(StandardScaler(), MLPClassifier()) # For classification
nn_r = make_pipeline(StandardScaler(), MLPRegressor()) # For regressionConclusions
Scaling is a very important Preprocessing transformation that can affect the training phase dramatically. If it’s not performed properly, the results of the model will surely be unreliable. That’s why it’s important to use the proper normalization technique when the model requires it.