

Feature selection is always a challenging task for data scientists. Identifying the right set of features is crucial for the success of a model. There are several techniques that make use of the performance that a set of features gives to a model. One of them is the sequential feature selection.
What is sequential feature selection?
Sequential feature selection is a supervised approach to feature selection. It makes use of a supervised model and it can be used to remove useless features from a large dataset or to select useful features by adding them sequentially.
The algorithm works according to these steps:
- Select, from the dataset, the feature that maximizes the average performance of your model in k-fold cross-validation. This dataset is made by only one feature.
- Add a second feature to your dataset according to the same principle (maximization of CV performance of the model)
- Keep adding features to the dataset until the desired number of features is reached or performance doesn’t improve significantly
This is a forward approach because we start with 1 feature and then we add other features. There’s a backward approach as well, that starts from all the features and removes the less relevant ones according to the same maximization criteria.
Since, at each step, we check the performance of the model with the same dataset with the addition of each remaining feature (one by one), it’s a greedy approach.
The algorithm stops when the desired number of features is reached or if the performance doesn’t increase above a certain threshold.
Advantages and disadvantages
The main advantage is that it is actually able to find a very good set of features according to the given model. Moreover, it merely works on model performance, so it doesn’t need the model to give us its own interpretation of feature importance like, for example, Random Forest or Lasso regression. It works with every model and this is a great advantage.
The main disadvantage is related to the greedy approach. As it’s easy to figure out, it’s computationally expensive, especially if you work with the backward approach and you have hundreds of features.
Moreover, selecting the features according to the performance doesn’t always guarantee the best set of features. For example, this approach doesn’t remove collinearity properly.
Finally, the entire procedure relies on the use of the proper performance metric (that is crucial for any supervised machine learning problem) and the choice of the threshold to apply to stop the selection.
The advantages and disadvantages of such a procedure must be taken into account according to the project we’re working on.
An example in Python
Let’s see an example using Python programming language. For this example, we’ll work with the breast cancer dataset of scikit-learn >= 1.1.
Let’s import some objects and the SequentialFeatureSelector object itself, that performs the feature selection algorithm.
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancerLet’s import a classification model, for example a Gaussian Naive Bayes model.
from sklearn.naive_bayes import GaussianNBLet’s split our dataset into training and test.
X,y = load_breast_cancer(return_X_y = True)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)Now, let’s apply the forward approach, with the automatic selection of the 4 best features. We’ll use the AuROC score for measuring the performance and a 5-fold cross-validation
selector = SequentialFeatureSelector(GaussianNB() ,n_features_to_select=4, direction='forward', scoring="roc_auc", cv=5)
selector.fit_transform(X_train,y_train)As expected, 4 features have been selected.

As we can do with every feature selector object of scikit-learn, we can use the “get_support” method of the selector to get the names of the selected features.
feature_names = load_breast_cancer()['feature_names']
feature_names[selector.get_support()]
Now, let’s try a different approach. Let’s make the algorithm choose the best set of features according to the balanced accuracy score and a stopping threshold of 1%. So, if the selection of any feature at each stage doesn’t improve this score by at least 1%, the algorithm stops with the features that have been identified until then.
selector = SequentialFeatureSelector(GaussianNB(), n_features_to_select='auto', direction='forward', scoring="balanced_accuracy", tol=0.01, cv=5)
selector.fit_transform(X_train,y_train)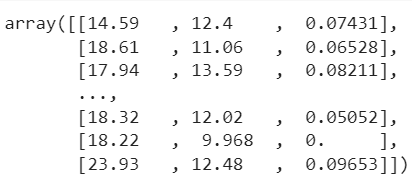
The selector has chosen 3 features. Their names are:

A similar task can be accomplished in a backward fashion by setting the “direction” argument to “backward”.
Conclusions
Sequential feature selection can be a very useful tool in a data scientist’s toolbox. However, we must take into account its complexity and computational speed, which is very low. I suggest using an automatic approach to select the best number of features and, generally speaking, using a forward approach could be the best thing. That’s because if we start from a huge number of features, the performance of the model might be affected by the curse of dimensionality and be unreliable for any purpose, including feature selection. The forward approach, on the contrary, starts from a small number of features and keeps adding them until it finds a good set. That can reduce computational time and give more reliable results.



