I’ve just introduced monthly payments for my learning paths and have other plans and ideas for the last part of this year.


Online courses and lessons about data science, machine learning and artificial intelligence
Online courses and lessons about data science, machine learning and artificial intelligence
I’ve just introduced monthly payments for my learning paths and have other plans and ideas for the last part of this year.
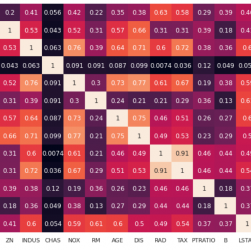
Collinearity is a very common problem in machine learning projects. It is the correlation between the features of a dataset and it can reduce the performance of our models because it increases variance and the number of dimensions. It becomes worst when you have to work with unsupervised models. In order to solve this problem, I’ve created a Python library that removes the collinear features.
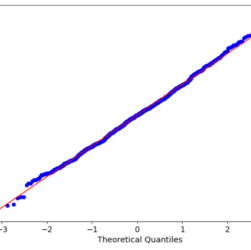
Data scientists usually need to check the statistics of their datasets, particularly against known distributions or comparing them with other datasets. There are several hypothesis tests we can run for this goal, but I often prefer using a simple, graphical representation. I’m talking about Q-Q plot.

In binary classification problems, we usually convert the score given by a model into a predicted class applying a threshold. If the score is greater than the threshold, we predict 1, otherwise, we predict 0. This threshold is usually set to 0.5, but is it correct?
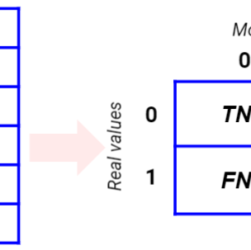
When we have to work with a binary classification problem, we often have to choose the performance metric that represents the generalizing capability of our model. There’s no universal metric we can use, since it strongly depends on the problem we are building our model for.

In binary classification models, we often work with proportions to calculate the accuracy of a model. For example, we use accuracy, precision and recall. But how can we calculate the error on these estimates? Are two models with 95% accuracy actually equivalent? Well, the answer is no. Let’s see why.

I often meet students that start their journey towards data science with Keras, Tensorflow and, generally speaking, Deep Learning. They build tons of neural networks like crazy, but in the end they fail with their models because they don’t know machine learning enough nor they are able to apply the necessary pre-processing techniques needed for making neural networks work.
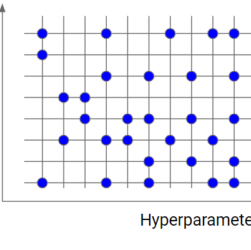
Hyperparameter tuning is one of the most important parts of a machine learning pipeline. A wrong choice of the hyperparameters’ values may lead to wrong results and a model with poor performance.
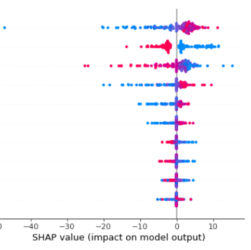
Neural networks are fascinating and very efficient tools for data scientists, but they have a very huge flaw: they are unexplainable black boxes. In fact, they don’t give us any information about feature importance. Fortunately, there is a powerful approach we can use to interpret every model, even neural networks. It is the SHAP approach.
Google Sheets is a very powerful (and free) tool for creating spreadsheets. I’ve almost replaced LibreOffice Calc with Sheets, because it’s very comfortable to work with. Sometimes, a data scientist has to pull some data from a Google Sheet into a Python notebook. In this article, I’ll show you how to do it using just Pandas.