

I often meet students that start their journey towards data science with Keras, Tensorflow and, generally speaking, Deep Learning. They build tons of neural networks like crazy, but in the end they fail with their models because they don’t know machine learning enough nor they are able to apply the necessary pre-processing techniques needed for making neural networks work.
Here’s why, if you start your career as a data scientist, you don’t need to start with Deep Learning.
Don’t start with the model
Data Science is about data, not about models. So, focusing on Deep Learning is like focusing on the models and that is wrong. You must focus on proper Exploratory Data Analysis and Pre-processing before using any model. A good visualization can make us reach good results before using any neural network because our purpose is to extract information from data. So, do yourself a favor and don’t start a machine learning project with neural networks nor any other model.
Neural networks are hard to train
Neural networks have several hyperparameters and, due to the fact that they have hundreds of weights to optimize, they need large datasets and computation time to give good results. In general, you never have enough data and you don’t have so much time to train a model, so starting with neural networks can be a wrong idea. The good idea is to start with a simpler model and increase the complexity if necessary, keeping the neural networks as a last step.
There are more models than neural networks
Everything depends on the particular case, but if you have tabular data, maybe you can find more powerful models than neural networks. For example, a good decision tree could be fine. The training can be faster and the results can be better. There are situations in which neural networks work better than other models, but when we have to work with tabular data we have a set of several models we can use instead of neural networks. Start with linear models, then move to KNN and Bayesian models, then Decision Trees and SVM. At this point, you have the knowledge to study ensemble models and, only at the end, you can focus on neural networks.
Neural networks are blackboxes
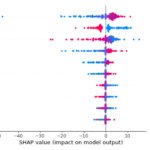
Let’s face it. Neural networks are unexplainable and explaining our model is one of the most complex tasks in machine learning. I’ve written an article about how to explain neural networks using SHAP, but it’s often more useful to work with a model that gives us its own interpretation of feature importance without using other techniques. Decision trees are such kind of models and that is why they are very used. Neural networks cannot be explained clearly by themselves and this is a great drawback. So, if we use neural networks, let’s keep in mind that we’ll have to explain them in some difficult way after we have trained them.
When are neural networks useful?
Neural networks become useful when you master data pre-processing and machine learning and you have a non-tabular problem to solve. For example, image classification using CNN or time series analysis using LSTM. Another use is, for example, sequence-to-sequence processing like the one used in language translators. In some special cases, a feedforward neural network may help you with your tabular dataset if the correlations between the features and the target are non-linear and non-trivial. If the other models fail and you have strong evidence that a correlation between the features and the target exists, you can start using a neural network, starting with a single hidden layer and adding more and more layers sequentially. If you start with neural networks, you lose the opportunity to have an explainable model that can be faster to train and give useful results as well.
Conclusions
Neural networks are a kind of science by themselves, but they are very sensitive to pre-processing and to the shape of our dataset and sometimes they don’t give us the results we could expect with a simpler model. When we start studying data science, it’s necessary to start with simple models and then reach neural networks only when we master the other techniques, particularly pre-processing and hyperparameter tuning. After we achieve this knowledge, we figure out that neural networks aren’t needed as often as people say, but are necessary only for particular tasks.


Really helpful
Thanks for sharing the information. It’s really helpful to those who are planning to learn Data Science
I hope this helps everybody who wants to learn data science. Thanks!
good content ,helped me alot.thank you
NN and are good finding patterns in data what so ever and way better as human is ever capable to process. But to efficiently use it one have to master it at university degree with god coding knowledge. There is no easy way around. Open source is much much harder to use as some whole commercial solutions in this field. I have try to use so called “easy” visual programming in Orange/Quasar, Knime and RapidMiner, as it turns out, not so easy at all (quirks and quarks with possibilities that don’t work well or don’t work at all but connections are allowed, also with questionable proper data input and u don’t know why is that so). Lack of proper advanced tutorials/examples for it (base tuts aren’t even good for start on). This should be much more easy to use as using NN libraries and API’s in some heavy weight NN. Learning to use NN is like try to fail every time. And is frustrating a lot. At the end i give up.