Data Science has entered the world of big companies, where data is. Managers of such companies often ask things that they don’t actually need and forget to pretend the only useful things to have.
“I want an algorithm per month”. Yes, I once heard somebody saying something like that and I’m afraid I’m not alone. How many times did a manager ask you to build algorithms? Everything seems related only to algorithms like they are the only thing that’s worth it.
But algorithms are not everything, nor they are the most important thing. There’s a world beyond them and it’s more interesting. So, if you are a manager and have to hire a data scientist, do a favor to your company and start asking for these things.
Data analysis
A data scientist working for your company must have a huge data analysis background, with solid skills. Data must be analyzed before applying any algorithm, so your data scientists must handle data in every shape and format, from SQL tables to JSON documents. Yes, SQL. SQL is not dead and your data scientists must master it like statistics, pivoting and KPI generation.
Data visualization
You can’t spend time looking at numbers or tables. You must take decisions in a fraction of a second, so a data scientist must have the proper data visualization skills. Your DS must be able to represent the information using charts and other visualization tools. A very good and explanatory chart is far better than a Powerpoint slide full of text and numbers. Pretend charts, easy-to-read visualizations and simple dashboards. The right charts can make a difference in a project and are sometimes the only deliverable you’ll ever need.
Information first
A data scientist extracts the information that is hidden behind data. Remember: data is a container, information is the content. You know your container, so the data scientist must be able to open it and reveal what’s inside. You are a manager, you need information. There’s no way to escape this truth. Business is made by people that handle the information according to their experience. So, don’t ask for tables of data or Excel/CSV files. Managers shouldn’t query anything. They must be given the correct information in a simple and synthetic way, for example with visualizations. So, be sure that your data scientist knows the difference between data and information and, please, be sure to know it yourself first.
Pre-processing
Data must be handled properly, like Venetian glass. Pre-processing is that set of techniques that makes your data scientist handle data in order to give them the proper shape. It’s an important skill and must be mastered, otherwise the glass you get won’t have the right shape and must be destroyed and crafted again. So, ask your data scientists which pre-processing pipeline they usually adopt. The correct answer is cleaning, encoding, transforming, feature selection for dimensionality reduction. If your data scientists don’t know what I’m talking about, let them see my online course about pre-processing.
Features are everything
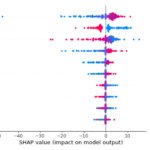
Features are the most important part of a data science project related to machine learning. Features, not the models. Data scientists must select the features properly using the necessary feature selection techniques. It’s very important and you cannot derogate this. A reasonably small number of features will make you extract the information behind data that explains “why” things happen. Data explain “what” happens, feature importance analysis may help you understand “why”. Some techniques for reducing the number of features are, for example, Recursive Feature Elimination and FIlter-based feature selection. After the model is ready, you must calculate feature importance using, for example, some techniques like SHAP. This way, you see how features interact with each other to give the final result. That’s a very huge piece of business information. I explain the SHAP technique and other feature importance approaches in my online course about machine learning.
Tools
Data scientists are craftsmen of data and information, so they must be able to use several tools. According to my experience, Python is the industry standard of Data Science. Then several libraries come, like Pandas, NumPy, Matplotlib, Seaborn. For Deep Learning, ask for Keras and Tensorflow, with PyTorch as an option. Some data scientists may know R, which is fine but may not be suitable for your production ecosystem if your company has always used Python. So, these are the technologies a Data Scientist must know.
Finally, the models
Don’t think neural networks will solve all your problems. Please, don’t do that. Neural networks are a fascinating field of artificial intelligence, but they are not the simplest models possible, nor they are able to explain anything. Remember: the model must make correct predictions that must be stable over time and over unseen data and must help you understand the business information better. Well, neural networks rarely satisfy any of these conditions. With a few records dataset, the trained neural network may overfit data and be unstable. Obviously, neural networks don’t help explaining anything, because they are black-boxes. Instead, ask your data scientists if they use simpler models that are easier to train, that make stable results and are explainable. Tree-based models, Bayesian models and linear models are good answers to this question. Ask them how they make a model’s results stable over time. The correct answer is “I use ensemble models to reduce variance”. Don’t forget that simple models always work better than neural networks when you have to work with tabular data. If you work with images, sounds and complex time series, neural networks are almost the only possible choice. But your company probably has a large data warehouse, so you deal with tabular data.
Conclusions
In this article, I wanted to help managers ask the right things to their data scientists or aspiring employees. Too many failures happen every day because managers don’t ask for the right things. Technology helps to reach a good goal, but cannot replace asking the right questions.