
When we have to work with a binary classification problem, we often have to choose the performance metric that represents the generalizing capability of our model. There’s no universal metric we can use, since it strongly depends on the problem we are building our model for.
Three very common metrics are precision, recall and accuracy. I talk about several performance metrics in my online course on supervised machine learning with Python, but in this article I’ll give you a brief introduction about these three specific metrics. Let’s see how they work.
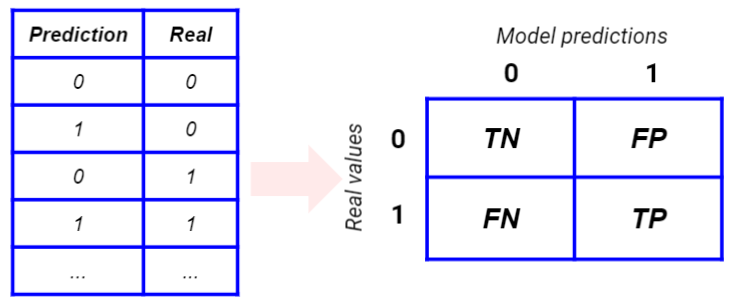
The confusion matrix
When we deal with a classification problem, we can build the so-called confusion matrix. It’s a cross table that mixes real and predicted values building an NxN matrix, where N is the number of classes. For our examples, we can talk about a binary classification problem, so we have 2 classes.
For a perfect model, we expect a diagonal matrix. The off-diagonal elements (the falses) are mistakes made by our model, so we would like them to be as few as possible. The correct predictions (the trues) are the most important part of the confusion matrix. The positives are those records for which the model has predicted 1, while the negatives are those records for which the model has predicted 0. Combining trues/falses and positives/negatives we get the True Positives, True Negatives, Falce Positives, False Negatives.
True Positives and True Negatives are events that have been correctly classified by our model. False Positives are false 1s and False Negatives are false 0s.
Using these 4 numbers, we can build a lot of metrics that can be used to assess the goodness of a model. Let’s see some.
The accuracy
Accuracy is the fraction of successful predictions with respect to the total number of records.
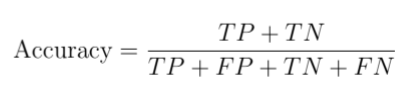
This is the most common performance metric, because it gives us a clear understanding of how often our model is true. It’s very useful when you give the same importance to 0 and 1, but you have to be careful when you use it, because if the dataset is unbalanced, the class with the highest number of records will dominate the fraction and it’s not often a good idea. A very high number of 0s will create a bias over the 1s and biases are not what we need.
So, use accuracy only if you have balanced datasets and you give the same importance to 0s and 1s.
Precision
Precision is a measure of the probability that an event classified by our model with 1 has been correctly classified. So, we take all the events that the model has predicted a 1 (the Positives) and calculate how often the model has been true.
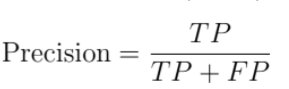
Precision is very useful when you have a model that starts some kind of business workflow (e.g. marketing campaigns) when it predicts 1. So, you want your model to be as correct as possible when it says 1 and don’t care too much when it predicts 0. That’s why we see only the second column of the confusion matrix, which is related to a prediction equal to 1.
Precision is very used in marketing campaigns, because a marketing automation campaign is supposed to start an activity on a user when it predicts that they will respond successfully. That’s why we need high precision, which is the probability that our model is correct when it predicts 1. Low values for precision will make our business lose money, because we are contacting customers that are not interested in our commercial offer.
Recall
Recall is the fraction of correctly classified 1s among all the real 1s.
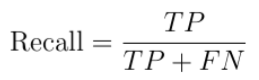
Recall is very used when you have to correctly classify some event that has already occurred. For example, fraud detection models must have a high recall in order to detect frauds properly. In such situations, we don’t care about the real 0s, because we are interested only in spotting the real 1s as often as possible. So, we’re working with the second row of the confusion matrix.
Common uses of recall are, as said, fraud detection models or even disease detection on a patient. If somebody is ill, we need to spot their illness avoiding the false negatives. A false negative patient may become contagious and it’s not safe. That’s why, when we have to spot an event that already occurred, we need to work with recall.
Conclusions
Accuracy, precision and recall are three metrics that can be built upon the confusion matrix. We can use accuracy when we are interested in predicting both 0 and 1 correctly and our dataset is balanced enough. We use precision when we want the prediction of 1 to be as correct as possible and we use recall when we want our model to spot as many real 1 as possible. Choosing the correct metric for our model can actually increase its predictive power and give us a great competitive advantage. As long as we have a clear idea of what our model must do, we can select one of them without doubts when we have to select a model or during hyperparameter tuning phase.




Hello! I simply would like to offer you a big thumbs up for the great information you’ve got right here on this post. I am returning to your site for more soon.