We’ve seen strong growth of Deep Learning techniques in the past few years. Thanks to technologies like Tensorflow and Keras, neural networks have become accessible by anybody in the world. But is Deep Learning really useful for you?


Online courses and lessons about data science, machine learning and artificial intelligence
Online courses and lessons about data science, machine learning and artificial intelligence
We’ve seen strong growth of Deep Learning techniques in the past few years. Thanks to technologies like Tensorflow and Keras, neural networks have become accessible by anybody in the world. But is Deep Learning really useful for you?

I have a Master’s Degree cum laude in Theoretical Physics. When I started my journey into data science, I figured out how useful it is for this kind of job.

Histograms are a very useful tool when we want to give a quick sight to the shape of our data. However, we always have to choose the right number of bins.

When we measure something, we always have to calculate the uncertainty of the result. confidence intervals are a very useful tool to calculate a range in which we can find the real value of the observable with a certain confidence.
Identifying outliers is a very common task in data pre-processing. A simple method for identifying them is using the Interquartile Range.
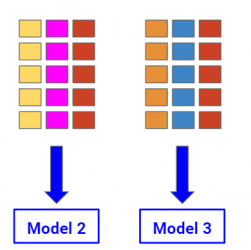
Data scientists usually search for a model that has the highest accuracy possible. However, they should focus on another term too, which is stability. In this article, I explain what it is and how to increase it using a technique called “bagging”.

Feature selection has always been a great problem in machine learning.
In this article, I’ll show how to perform feature selection using a random forest model in Python.

Data Science and machine learning are two wonderful and exciting disciplines and are a great part of our lives. Sometimes people confuse them, but they are quite different things.

I’m very glad to announce that I’ve published my new free course! The topic is the Exploratory Data Analysis using …

Data Science has entered the world of big companies, where data is. Managers of such companies often ask things that they don’t actually need and forget to pretend the only useful things to have.