

Models are very powerful tools to be used in several web applications. The general approach is to make them accessible by using REST APIs. In this article, I’ll talk about a model that can be created in Python and then deployed in pure Javascript.
Why Javascript?
Machine learning models are often created in Python or R, so why should we use Javascript? Because Javascript runs on our user’s browser, so deploying a model in this language allows us to decentralize the computational effort. Using Javascript, we’ll no longer need REST APIs to use our model, which is a very useful thing because it simplifies our application’s architecture. If we still want to make our model work server-side (for example, if we don’t want to make it accessible by the user), we can run it on Node.js in order to benefit from the use of Javascript. So, these are the advantages of using Javascript for deploying a model.
The framework
So, should we create our model in Javascript? Well, no. The idea is that we still need Python to create our model, but we can translate it into Javascript later. This way, we’ll benefit from all the power of Python programming language and its libraries. We’ll then deploy only the final result in Javascript.
The model
In this article, I’ll create a simple language detection model in Python and then deploy it in Javascript, creating a simple web application that detects the language of a text while the user writes it. I have previously talked about a language detection model using Naive Bayes models. In this article, I’ll use the same dataset, but a different model (a logistic regression).
You can find the whole notebook on my GitHub repo.
The dataset is my Italian short novel “L’isola del male” and its English translation. For the German language, I’ll use “Also Sprach Zarathustra” by Friedrich Nietzsche. So, the languages used in this model are Italian, English and German.
First, let’s clean the dataset using a custom function that takes a txt file and returns a list of sentences.
def file2sentences(filename):
txt = ""
with open(filename,"r",encoding="utf-8") as f:
txt = f.read()
txt = txt.replace("?",".")
txt = txt.replace("!",".")
txt = txt.replace("»","")
txt = txt.replace("«","")
txt = txt.replace(":","")
txt = txt.replace(";","")
txt = txt.replace("...",".")
txt = txt.replace("…",".")
txt = txt.replace("\n",".")
txt = txt.replace(" "," ")
txt = txt.replace("“","")
txt = txt.replace("„","")
sentences = txt.split(".")
for i in range(len(sentences)):
sentences[i] = sentences[i].strip()
sentences = [x for x in sentences if x != ""]
return sentencesThen, let’s load our files and attach the correct labels.
italian = file2sentences("isola del male.txt")
english = file2sentences("island of evil.txt")
german = file2sentences("also sprach zarathustra.txt")
X = np.array(italian + english + german)
y = np.array(['it']*len(italian) + ['en']*len(english) + ['de']*len(german))So, X contains the sentences and y contains the language label.
Now we can split our dataset into training and test.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)The core of my original article was to use, as features, the character bigrams. For this example, I’ll calculate them and create a binary feature that is equal to 1 if the bigram is present in the sentence and 0 if it’s not.
cnt = CountVectorizer(analyzer = 'char',ngram_range=(2,2),binary=True)
cnt.fit(X_train)Now comes the model. For this example, I’ll use a Logistic Regression
model = LogisticRegression()
model.fit(cnt.transform(X_train),y_train)
y_pred = model.predict(cnt.transform(X_test))Let’s see the classification report.
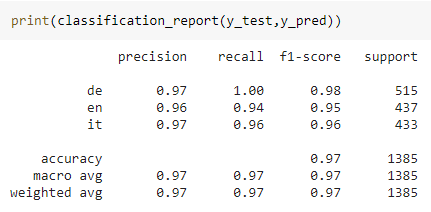
Results are pretty impressive, for a simple model like ours. High values of the recalls tell us that the model is able to detect a language efficiently.
Now, we have to translate this Python model into Javascript.
Model conversion from Python to Javascript
To translate a sklearn model into Javascript, I have used the m2cgen library, which allows such kind of conversion from Python into different languages. Javascript is one of them.
Let’s first install it:
!pip install m2cgenNow we can import it.
import m2cgen as m2cIn order to convert our model, we must increase the recursion limit. This is due to the fact that we have 800+ features.
import sys
sys.setrecursionlimit(10000)Finally, here’s the Javascript code of our model:
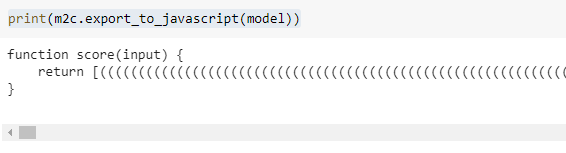
This function returns an array with the score for each class. The selected class will be the one with the highest score.
Now we have to implement the pre-processing part. We must first save the bigrams into a Javascript array.
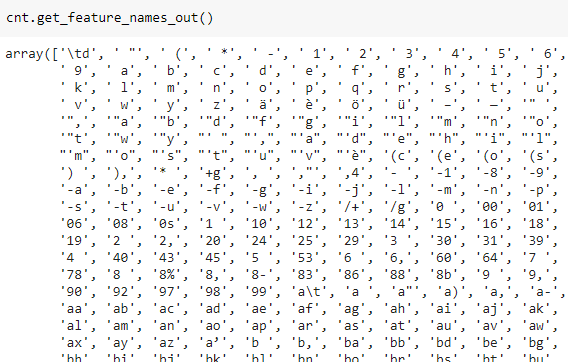
We now have to create the binary variables according to these bigrams. In Javascript, we can use this code in order to select the language according to the given model. bigrams and score function code is omitted because it’s pretty long.
function score(input) { ... }
bigrams = [...]
languages = ['de', 'en', 'it'];
function getLanguage(text) {
vect = [];
for (i = 0; i < bigrams.length; i++) {
vect.push(text.toLowerCase().indexOf(bigrams[i]) > 0 ? 1 : 0);
}
scores = score(vect);
return languages[scores.indexOf(Math.max(...scores))];
}
We can now embed everything into a simple HTML application.
The final application
We can build a simple web page with Bootstrap to manage the graphics and JQuery to update a language detection field that automatically updates the detected language while the user writes some text.
Here’s the JSFiddle application. Just go on the “Result” tab and start typing some sentences in the 3 languages. For example, “questa è una applicazione per riconoscere il linguaggio” for Italian, “this is an application to recognize language” for English and “Dies ist eine Anwendung zur Spracherkennung” for German.
It’s pretty impressive, even because not all the words of these sentences are used in the original corpus.
Conclusions
In this article, I’ve shown how to implement a simple machine learning model in Javascript starting from Python’s powerful sklearn library. This concept can be used to create, for example, server-side models in Node.js or client-side models that aren’t too CPU-expensive. We still get the benefits of Python’s libraries, but we are now able to translate our model into a client-side language, which can be useful for several purposes.



It does not work => Uncaught RangeError: Maximum call stack size exceeded
Uncaught RangeError: Maximum call stack size exceeded
If you run this in node.js it works you can’t run this in the browser
do you know how to avoid: ‘ The kernel appears to have died. It will restart automatically. ‘